

How can you effectively balance high-performance artificial intelligence with the growing global demand for environmental sustainability? As the tech landscape shifts, you will find that energy llm inference is now a critical metric for developers and business owners alike. This guide explores how to optimize models to ensure your inference efficiency optimizations remain both green and highly profitable. By understanding the underlying mechanics of GPU cycles and token generation, you can significantly reduce your operational costs while maintaining cutting-edge performance.
Why Is Sustainable LLM Deployment Essential in 2026?
The carbon footprint of modern AI is expanding rapidly, making sustainable LLM deployment a mandatory goal for any tech-forward firm. When you run a query, the hardware pulls significant power, meaning your energy llm inference costs can spiral without proper oversight. This high demand for compute power is currently straining data center energy grids from Silicon Valley to New York City.
To stay competitive against rising utility costs, you must prioritize various inference efficiency optimizations within your technical stack to ensure long-term viability. By shrinking model sizes through techniques like weight pruning and 4-bit quantization, you drastically reduce the GPU energy consumption required for every single user interaction during energy llm inference. This proactive shift doesn’t just protect the planet; it safeguards your margins by lowering the massive overhead of your sustainable AI inference infrastructure. As electricity prices fluctuate, having a lean, energy-sipping model architecture becomes a primary competitive advantage that allows you to scale your services without hitting the physical power ceilings that are currently stalling many unoptimized startups.
How Does LLM Energy Usage Impact Energy LLM Inference?
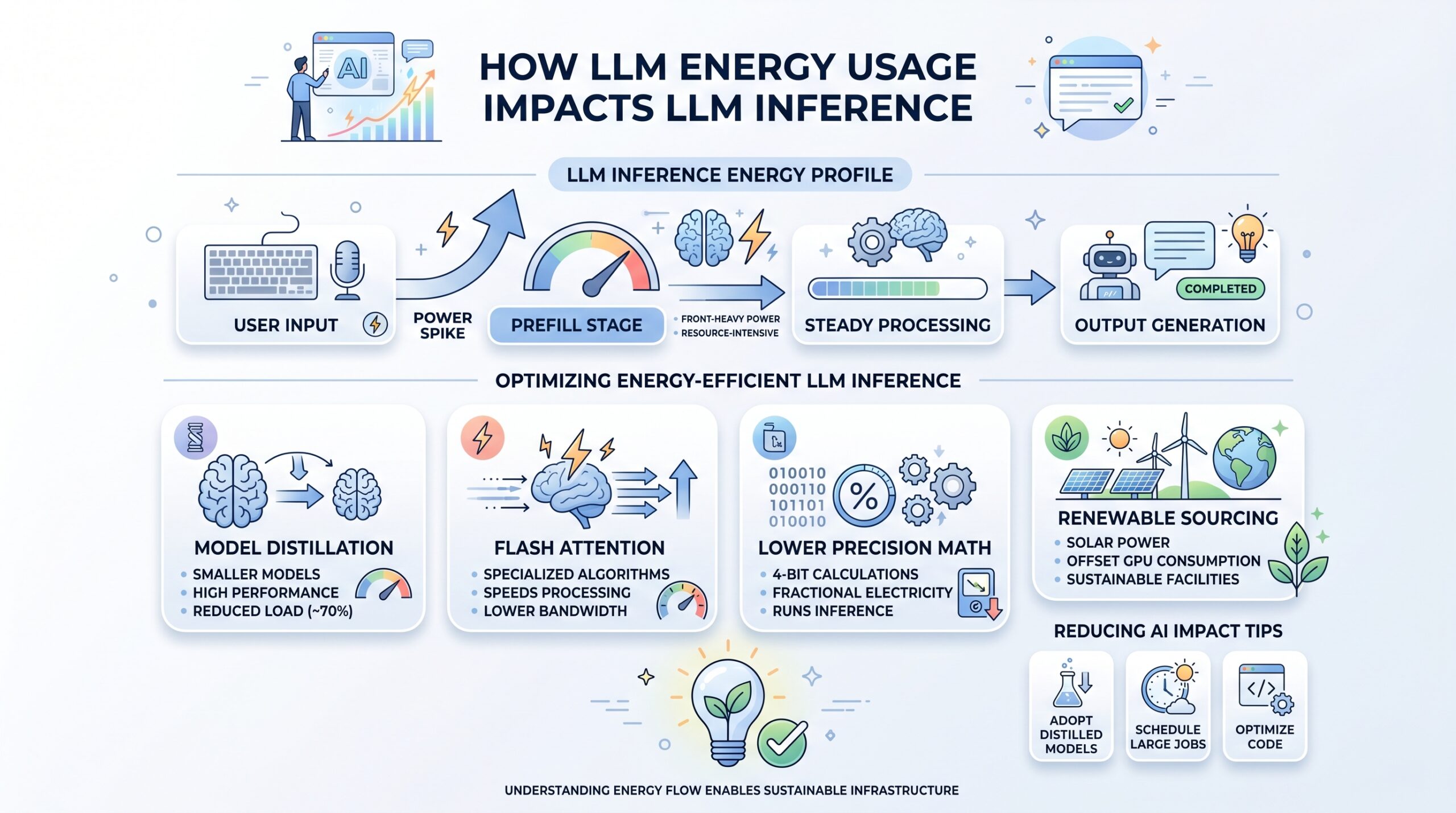
To truly optimize your technical stack, you need to understand how LLM energy usage fluctuates during a typical user session. Power consumption isn’t a steady stream; it spikes during the “prefill” stage, making your energy llm inference profile very front-heavy. Because processing is resource-intensive, data centers are rethinking their sustainable AI inference infrastructure to handle these unique electrical loads.
To mitigate these issues, industry leaders are focusing on several key areas to improve their energy efficient LLM inference engines and overall delivery speed:
- Model Distillation: You can train smaller models that maintain high performance while reducing energy llm inference loads by 70%.
- Flash Attention: These specialized algorithms speed up processing and lower the bandwidth needed for NLP inference workloads.
- Lower Precision Math: Switching to 4-bit calculations allows you to run energy llm inference with a fraction of the electricity.
- Renewable Sourcing: Many US facilities use solar power to offset the total GPU energy consumption and conversational AI impact.
By focusing on these areas, you ensure that your energy llm inference tasks are as lean as possible while still delivering the high-quality reasoning your customers expect. This smart approach to inference efficiency optimizations is the only way to scale your AI services without hitting a physical power ceiling in your local tech hub. When you implement memory-efficient kernels, you aren’t just saving power—you’re also reducing latency, which improves the user experience and lowers the churn rate for your AI-driven applications.
Is There a Difference Between Traditional and Energy LLM Inference?
If you want a competitive edge, you must recognize the performance gap between legacy systems and energy efficient LLM inference engines. In the past, hardware prioritized raw speed, but now, the cost of LLM energy usage dictates your long-term viability. Today, every energy llm inference task must maximize the “intelligence-per-watt” ratio to be sustainable.
The following table compares legacy deployment versus modern, green energy llm inference strategies:
| Feature | Traditional LLM Inference | Energy Efficient LLM Inference |
| Precision | High (FP32/FP16) | Optimized (INT8/NF4) |
| Architecture | Dense (All parts active) | Mixture-of-Experts (Sparse) |
| Power Use | Maximum Load | 60-80% Lower energy llm inference |
| Primary Metric | Raw Latency | Power-to-Performance Ratio |
| Carbon Impact | Heavy | Minimal via green prompt engineering |
By adopting these engines, you effectively cut the “compute waste” that plagues standard NLP inference workloads and drains your budget. This transition allows your energy llm inference tasks to run on smaller, more affordable hardware while still providing the high-quality answers your users have come to expect from top-tier AI. Using sparse architectures—where only the necessary parts of the model “brain” activate for a specific task—is the smartest way to manage your heavy GPU energy consumption in 2026. This architectural shift means your hardware stays cooler, lasts longer, and processes more queries per second, giving you a dual benefit of lower maintenance costs and higher throughput for your growing user base.
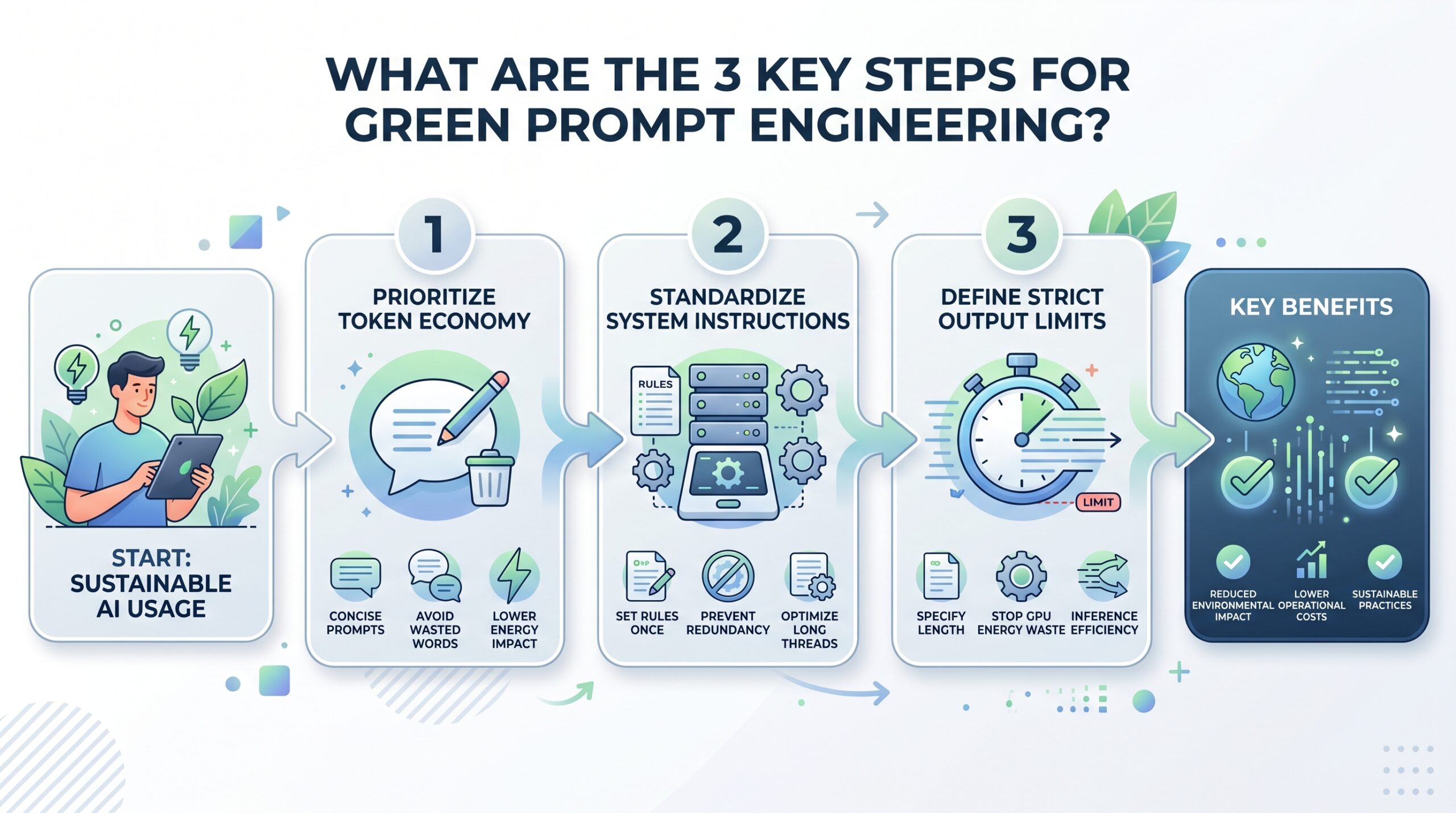
What Are the 3 Key Steps for Green Prompt Engineering?
- Prioritize Token Economy: You should write prompts that are direct and clear to avoid wasting cycles. Every extra word increases the conversational AI energy impact of the request and the total energy llm inference cost. By being concise, you directly lower the total LLM energy usage for that session.
- Standardize System Instructions: Instead of repeating rules, set them once in the system prompt. This prevents the model from wasting data center energy resources on redundant analysis. It is an effective way to lower the energy efficient LLM inference engines impact over long threads and optimize your energy llm inference.
- Define Strict Output Limits: Always tell the AI exactly how long the answer should be. This stops the GPU from wasting GPU energy consumption on unneeded tokens. This is the fastest way to achieve inference efficiency optimizations without changing hardware.
Mastering these techniques will help you lead a much more sustainable LLM deployment strategy across your entire organization. When your team uses green prompt engineering, the cumulative savings on your energy llm inference consumption can be massive, often rivaling the savings found in hardware upgrades. This ensures your NLP inference workloads stay within your company’s green energy budget while fostering a culture of efficient, high-impact AI usage that prioritizes quality over quantity in every generated response.
Why Is Energy LLM Inference Critical for the US?
Building a greener future requires an overhaul of the physical systems that facilitate energy llm inference tasks. Sustainable AI inference infrastructure is being pioneered in Austin and Seattle, where facilities are designed specifically to optimize data center energy. These innovations ensure that high LLM energy usage demand doesn’t lead to localized grid failures or waste.
We are also seeing a rise in custom AI chips built for energy efficient LLM inference engines that outperform general-purpose GPUs. These chips are much more effective than general processors because they are hard-wired for the specific mathematical matrices required in inference efficiency optimizations. When you combine this specialized hardware with better software-level sustainable LLM deployment tweaks, you get an energy llm inference system that is both faster and greener. As more US-based tech firms migrate to these custom silicon solutions, the national energy footprint of AI will begin to stabilize, allowing for continued innovation without compromising our national energy security or environmental goals.
How Can You Optimize NLP Inference Workloads for Energy LLM Inference?
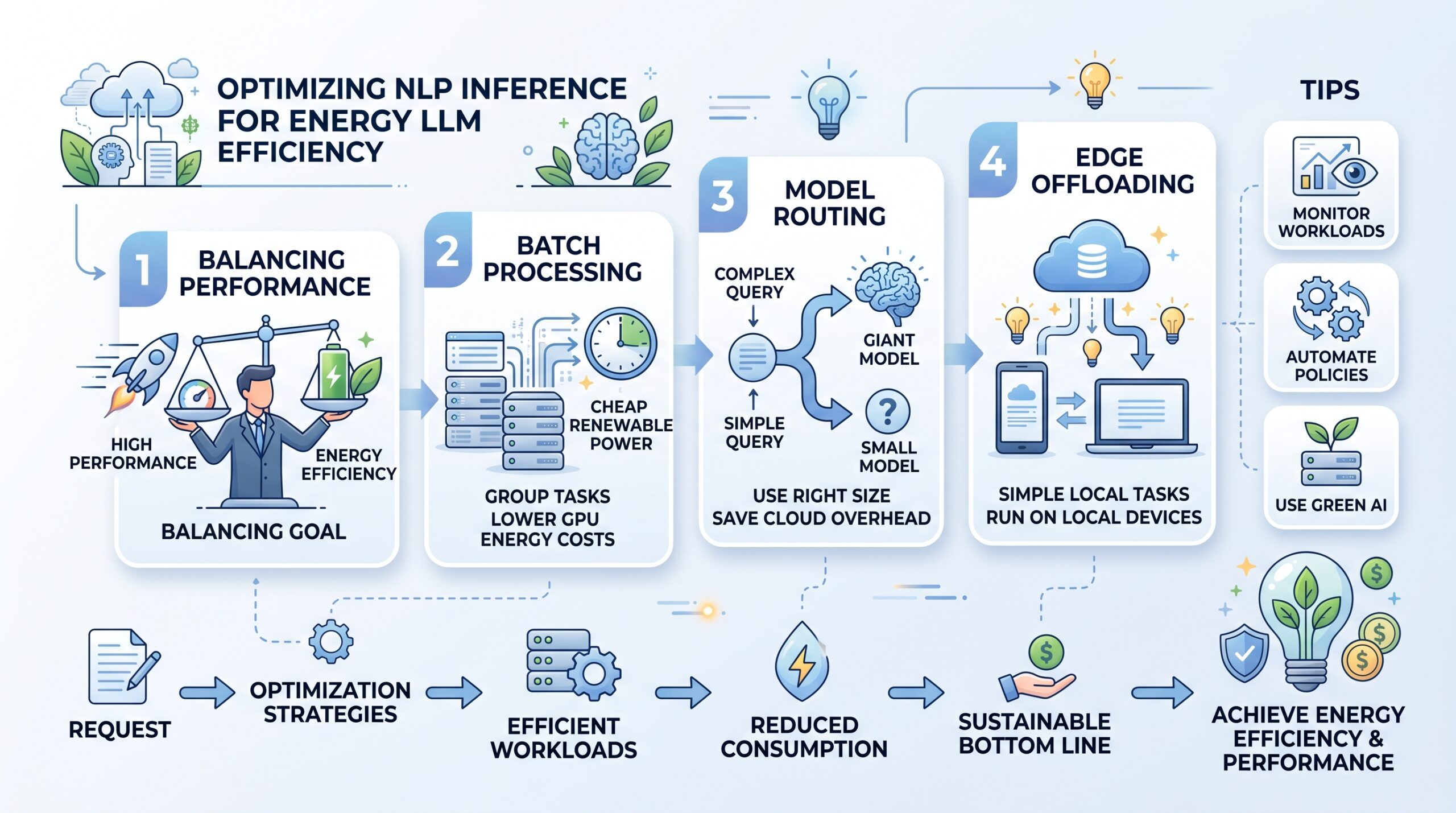
For tech managers, the goal is to balance high performance with your energy llm inference bottom line. You can optimize your NLP inference workloads by “batching” requests to ensure GPUs run at their most efficient capacity. This ensures that for every watt of data center energy, you get the maximum energy llm inference work done.
To achieve this, consider implementing these high-level strategies for your production environment:
- Batch Processing: Group tasks to run when renewable energy is cheaper, lowering your GPU energy consumption costs for energy llm inference.
- Model Routing: Use small models for simple tasks and only use energy llm inference on giant models for complex logic.
- Edge Offloading: Run simple tasks on local devices to save on cloud-based LLM energy usage and overhead.
By being strategic with your inference efficiency optimizations, you protect your business from sudden price spikes in the energy market. This forward-thinking approach to your conversational AI energy impact ensures your company remains a leader in the tech space. You will successfully navigate the complexities of modern energy llm inference while maintaining a standard of performance that keeps you ahead of the competition without overspending on compute resources.
Can AI Help Manage Future Energy LLM Inference?
In the future, the relationship between AI and power will be a two-way street for sustainable LLM deployment. We expect to see energy efficient LLM inference engines that are “grid-aware,” meaning they adjust based on green energy availability. This synergy will make sustainable AI inference infrastructure the standard for every major firm using energy llm inference.
The fusion of Green Tech and AI is the defining challenge of our era regarding the scalability of energy llm inference. By staying informed about breakthroughs in inference efficiency optimizations, you position yourself as a leader in a world that values both intelligence and sustainability. The most successful businesses of 2026 will be those that master the delicate balance of LLM energy usage and environmental impact, turning efficiency into a hallmark of their brand identity. As we look toward the next decade, the companies that thrive will be those that view energy as a finite resource to be managed with the same precision as their financial capital. For any more information on this topic, we can recommend you to check this article by clicking here.
Frequently Asked Questions
Does energy llm inference affect the speed of the AI?
In many cases, optimized energy llm inference is actually faster because models are smaller and calculations are more streamlined.
How much can I save by using green prompt engineering?
Businesses typically see a 20% to 30% reduction in LLM energy usage after implementing strict token management for energy llm inference.
Is there a specific tool for monitoring GPU energy consumption?
Yes, most cloud providers now offer dashboards to track the data center energy impact of your specific energy llm inference clusters.
Why is data center energy such a big topic for energy llm inference?
The massive amount of energy llm inference required is currently testing the limits of the US national power grid.
Can I run sustainable LLM deployment on my own servers?
Yes, by using open-source models optimized for energy efficient LLM inference engines, you can maintain green energy llm inference on-premise.
Here’s a cleaner, more reader-focused + blog exploration-driven rewrite with smoother flow and natural keyword usage:
Future Outlook: Mastering Sustainable Growth with Energy LLM Inference
The future of AI is increasingly tied to how efficiently we manage energy LLM inference. As demand for large-scale AI systems grows, businesses and developers must focus on optimizing performance without increasing energy costs. From improving inference efficiency to scaling sustainable deployments, the ability to balance innovation with energy awareness is becoming a key factor in long-term success. In today’s landscape, building smarter and more efficient systems is no longer optional—it is essential for staying competitive.
This shift is also driving new approaches in infrastructure design, where efficiency, cost control, and sustainability work together. As organizations continue to refine their strategies, staying informed about evolving technologies and best practices will help ensure your systems remain scalable, resilient, and aligned with future demands.
If you want to stay updated on the latest trends, tools, and innovations shaping energy LLM inference and AI sustainability, explore more of our blog content. We regularly share insights, updates, and expert perspectives to help you stay ahead in the rapidly evolving AI space.
Explore More:
Check our Official Website!
Category: Artificial Intelligence






















